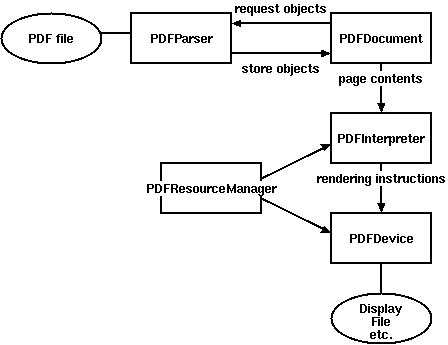
Figure 1. Relationships between PDFMiner classes
This document explains how to use PDFMiner as a library from other applications.
PDF is evil.
Because a PDF file is normally big and has a complex structure,
parsing a PDF as a whole is time-and-memory
consuming. Furthermore, not every part is needed for most PDF
processing. Therefore, PDFMiner takes a strategy of lazy parsing,
which is to parse the stuff only when it's necessary. To parse PDF
files, you need at least two classes: PDFParser
and PDFDocument. These objects work together.
PDFParser fetches (or parses) data from a PDF,
and PDFDocument stores it. You'll also need
PDFPageInterpreter to process the page contents
and PDFDevice to translate it to whatever you need.
PDF documents are more like graphics format, rather than text format. The contents in PDF are just a bunch of procedures that tell how to render the stuff on a display or paper. In most cases, it presents no logical structure such as sentences or paragraphs. So PDFMiner attempts to reconstruct some of them by performing layout analysis. Ugly, I know. Again, PDF is evil.
Figure 1 shows the relationship between these classes:
A typical way to parse a PDF file is the following:
from pdfminer.pdfparser import PDFParser, PDFDocument from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.pdfdevice import PDFDevice # Open a PDF file. fp = open('mypdf.pdf', 'rb') # Create a PDF parser object associated with the file object. parser = PDFParser(fp) # Create a PDF document object that stores the document structure. doc = PDFDocument() # Connect the parser and document objects. parser.set_document(doc) doc.set_parser(parser) # Supply the password for initialization. # (If no password is set, give an empty string.) doc.initialize(password) # Check if the document allows text extraction. If not, abort. if not doc.is_extractable: raise PDFTextExtractionNotAllowed # Create a PDF resource manager object that stores shared resources. rsrcmgr = PDFResourceManager() # Create a PDF device object. device = PDFDevice(rsrcmgr) # Create a PDF interpreter object. interpreter = PDFPageInterpreter(rsrcmgr, device) # Process each page contained in the document. for page in doc.get_pages(): interpreter.process_page(page)
Here is a typical way to use the layout analysis function:
The layout analyzer gives a "from pdfminer.layout import LAParams from pdfminer.converter import PDFPageAggregator # Set parameters for analysis. laparams = LAParams() # Create a PDF page aggregator object. device = PDFPageAggregator(rsrcmgr, laparams=laparams) interpreter = PDFPageInterpreter(rsrcmgr, device) for page in doc.get_pages(): interpreter.process_page(page) # receive the LTPage object for the page. layout = device.get_result()
LTPage" object for each page
in the PDF document. The object contains child objects within the page,
forming a tree-like structure. Figure 2 shows the relationship between
these objects.
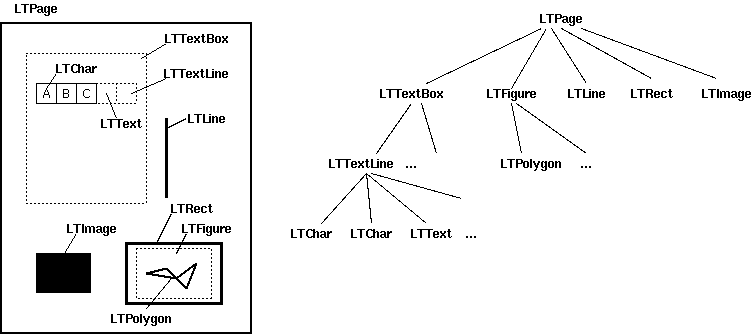
LTPage
LTTextBox, LTFigure, LTImage, LTRect,
LTPolygon and LTLine.
LTTextBox
LTTextLine objects.
LTTextLine
LTChar objects that represent
a single text line. The characters are aligned either horizontaly
or vertically, depending on the text's writing mode.
LTChar
LTText
LTChar object has actual boundaries,
LTText objects does not, as these are "virtual" characters,
inserted by a layout analyzer according to the relationship between two characters
(e.g. a space).
LTFigure
LTFigure objects can appear recursively.
LTImage
LTLine
LTRect
LTPolygon
PDFMiner provides functions to access the document's table of contents ("Outlines").
from pdfminer.pdfparser import PDFParser, PDFDocument
fp = open('mypdf.pdf', 'rb')
parser = PDFParser(fp)
doc = PDFDocument()
parser.set_document(doc)
doc.set_parser(parser)
doc.initialize(password)
# Get the outlines of the document.
outlines = doc.get_outlines()
for (level,title,dest,a,se) in outlines:
print (level, title)
Some PDF documents use page numbers as destinations, while others use page numbers and the physical location within the page. Since PDF does not have a logical strucutre, and it does not provide a way to refer to any in-page object from the outside, there's no way to tell exactly which part of text these destinations are refering to.